提取 PDF 文字
组件介绍
提取 PDF 文件中的文本内容
截图

属性说明
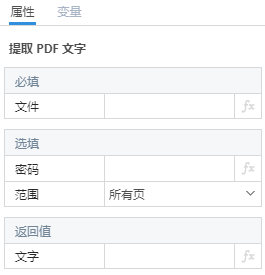
必填项
| 属性名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| 文件 | 字符串 | 空 | PDF 文件路径,可以点击右侧的文件夹图标进行选择 |
选填项
| 属性名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| 密码 | 字符串 | 空 | 如果文件设置了密码需要输入正确的密码 |
| 范围 | 下拉选项 | 所有页 | 需要进行转换的页码范围: ● 所有页 ● 部分页:连续多页 ● 单页:指定某一页 |
| 起始页码 | 数字 | 空 | 范围选择「部分页」时开始转换的页码, 为空、负数或者 0 默认为 1 |
| 结束页码 | 数字 | 空 | 范围选择「部分页」时停止转换的页码, 超过 PDF 实际页码默认为页码最大页 |
| 页码 | 数字 | 空 | 范围选择「单页」时的页码 |
返回值
| 名称 | 类型 | 说明 |
|---|---|---|
| 文字 | 字符串 | 提取的文本内容,只有图片时返回空字符串 |
组件示例
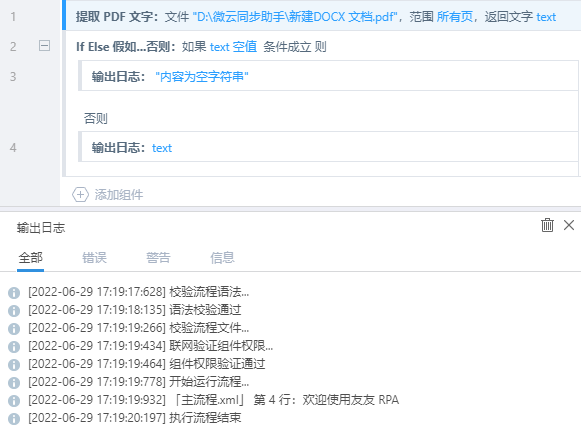
- 提取 PDF 文字:文件选择 pdf 文件,其他选项默认,返回值文本
text - if else 假如...否则:值
text,规则条件空值———判断文本内容是否为空字符串 - 运行结果:日志面板输出提取到的文本内容
注意事项
文件同时支持相对路径和绝对路径,相对路径以点斜杠 ./ 开头,代表该流程路径下文件夹,流程文件夹目录具体介绍详见流程发布文件大小上限。
「范围」属性选择「部分页」时,「结束页码」必须大于或者等于「起始页码」,否则会报错。